Graphical UI
Table of contents
How to use Zendro’s graphical user interface
Zendro’s graphical point-and-click user interface is accessible in a web browser, as a single page application (SPA).
To explore how it looks, you can look at the screenshots below, or even better try it out live! Just go to https://zendro.conabio.gob.mx/spa, where you will find a dummy Zendro instance we set up for you to try.
Zendro’s home graphical interface looks similar to the image below. But of course it can be customised (by the person who installed Zendro) to show what you prefer:

All data administration functions available in the graphical user interface are subjected to user based access control, meaning a user only sees the respective icons, buttons, and even model names in the main menu, if and only if she / he has the required access rights to the respective read or write operations.
Login
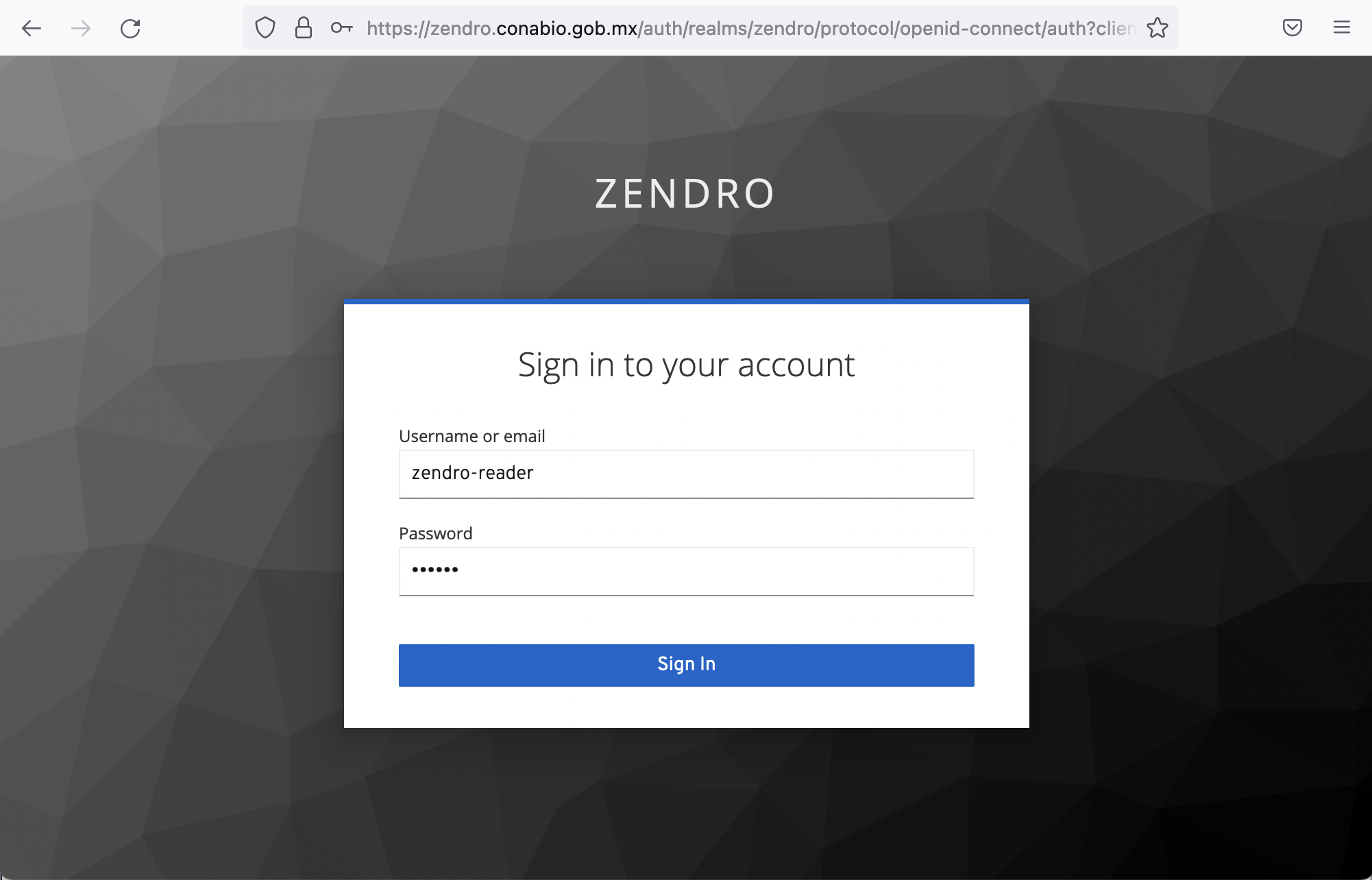
Clicking in LOGIN will prompt you for your username and password. Zendro’s graphical interface allows users to Create, Read, Update or Delete (CRUD) records, but you can decide which users can do what. For instance only one or two people on a research team may have edit access rights to create, update or delete records, while several other members of the team could be allowed to read.
We created a user with reading access rights for you to explore. You can login with the user shown in the image below and the password reader.
Exploring data
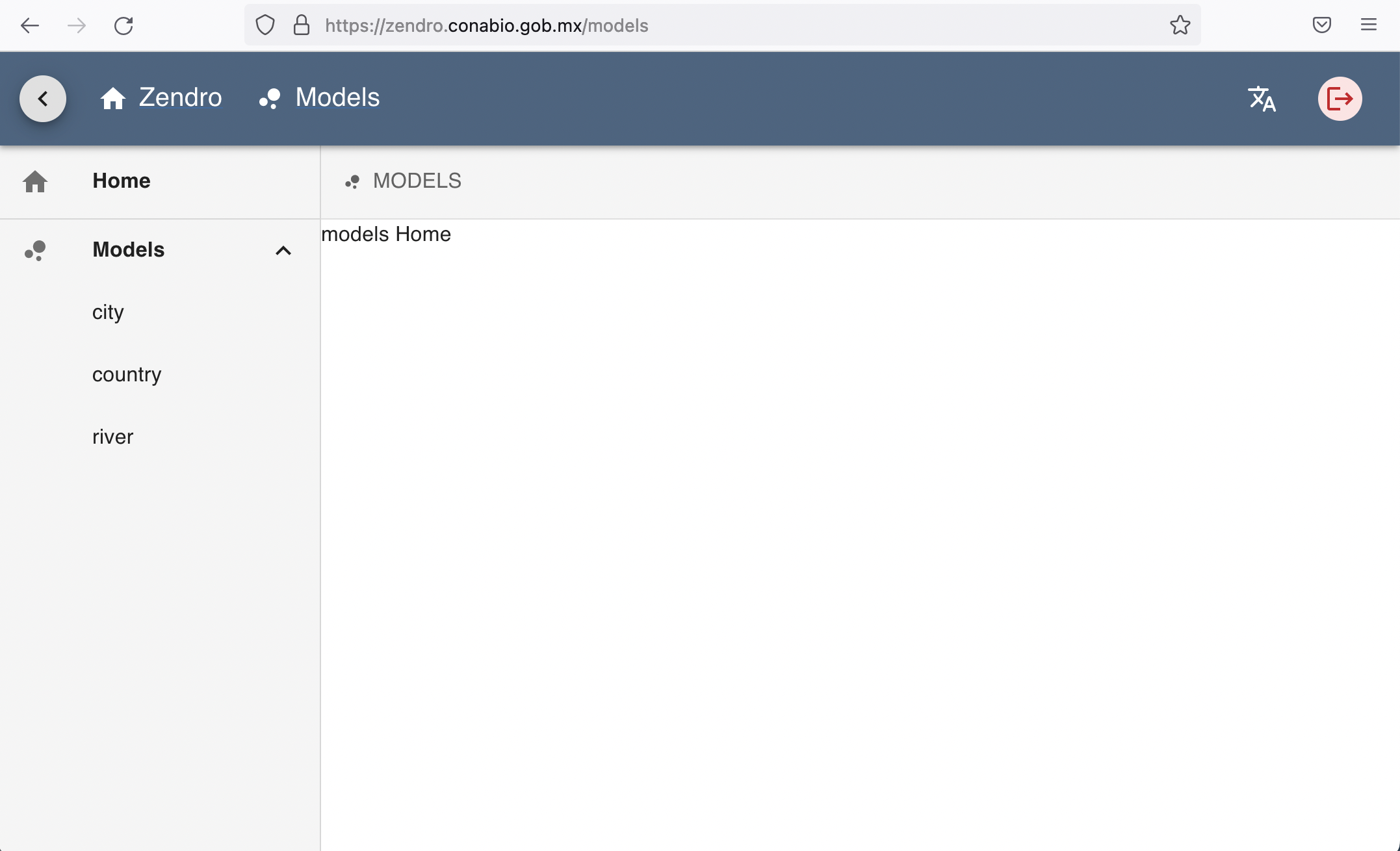
Upon successful sign-in in the graphical interface, the user is presented with an overview menu on the left, offering one entry per data model. That is, Zendro will create a table for each of the data models provided when setting it up.
In this dummy example the models are “City”, “River” and “Country”. The home is shown in blank by default, but you can use this area to add whatever you want, like models documentation or project introduction.
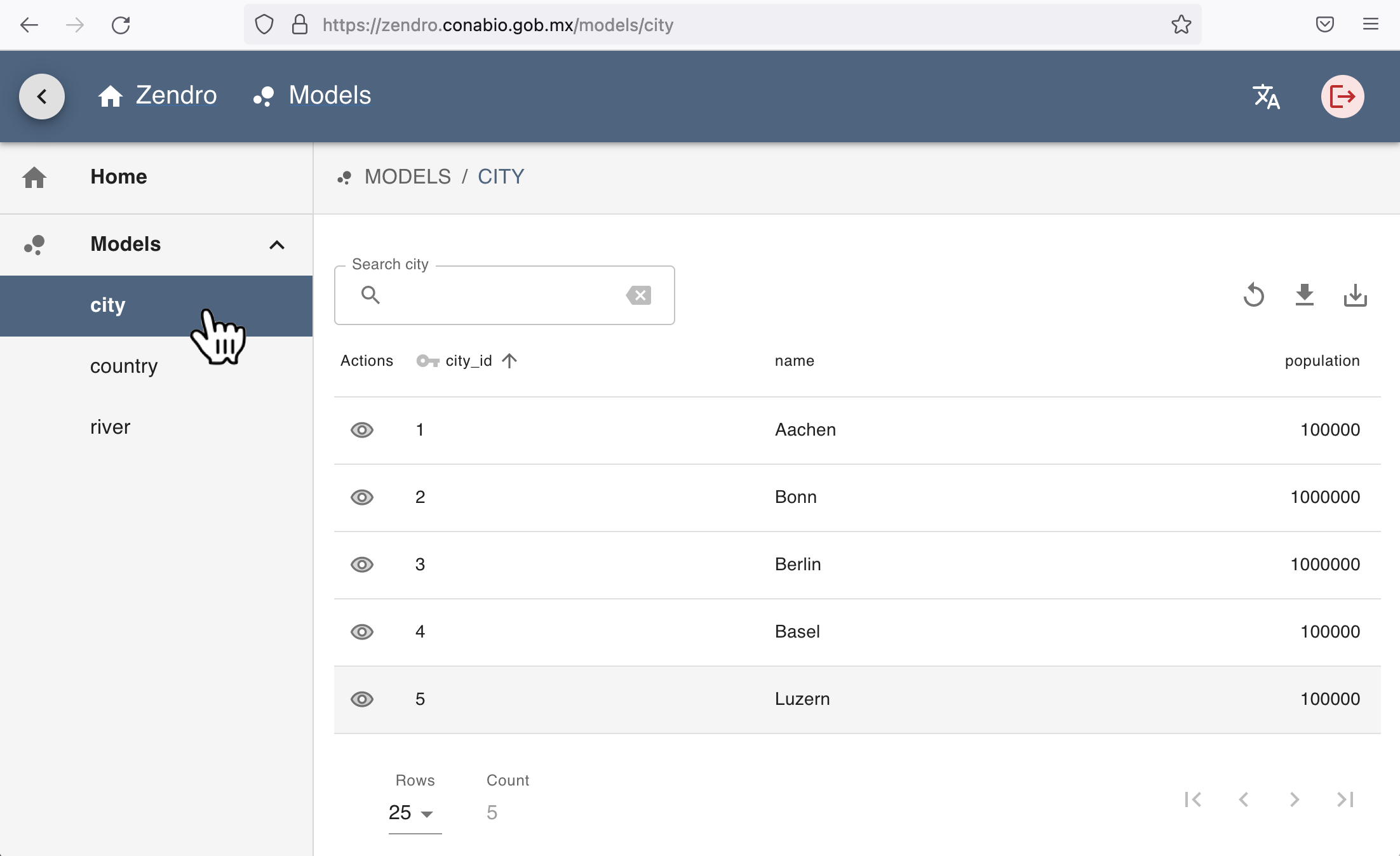
Clicking on a data model name will present the user with the main data model table, showing a column for each field in the data model (in this example “city_id”, “name” and “population” of the model “city”), and a row for each record.
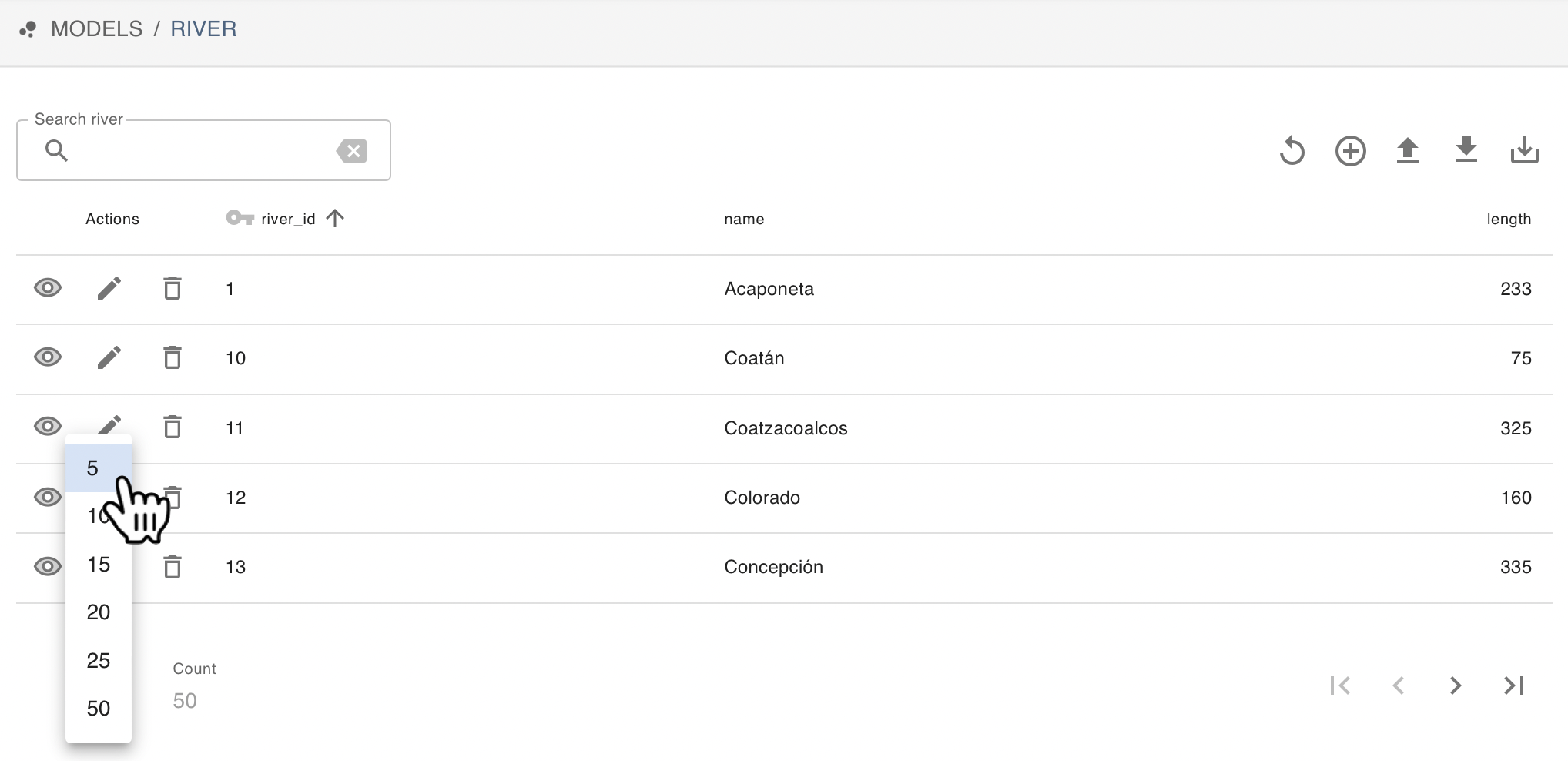
If you are exploring a table with lots of rows, you can modify the number of rows the table shows at a time by clicking on the number in the lower-left corner. The number of pages will be modified automatically to fit all the data to the desired number of rows per page. Try that in the river model:
At the bottom right of the table, the user can skip forward or backward through pages:

You can hide or expand the data models menu by clicking in the “>” icon:
Clicking on the column name will sort the data by that column in ascending alphabetical order. Above the table the user can enter search terms which will be matched against any column, if the respective field is of type string (text), and against any numeric columns, if the entered search term can be translated to a number.
For each record, the table offers the user the option to open the detailed view of a selected record (“eye” icon). Users with edit and delete permissions also see the option to edit (“pencil” icon) or delete the record (“trash” icon):
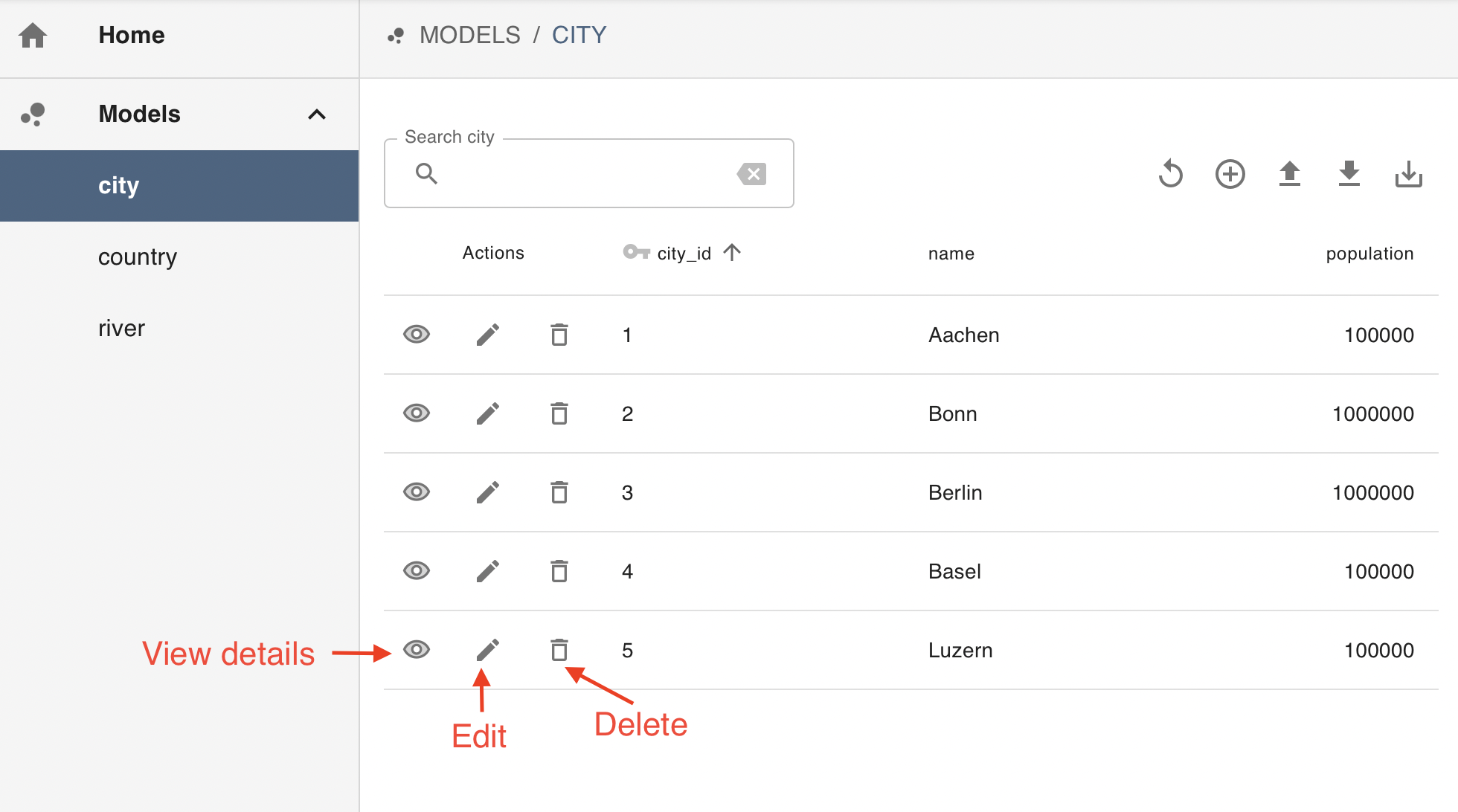
You may have noticed that you can only see the “eye” icon to go to the detailed view, but not the other icons. This is because the user we made public for this tutorial only has reader permissions and hence cannot modify the existing data.
Clicking on the “eye” icon leads to the detailed view, which enables full inspection of all details (“ATTRIBUTES” tab) that a single record has:
If the user has edit permissions, they would also see buttons for opening the edit and delete forms. See Editing data below for details.
In the detailed view, all users also see a tab called “ASSOCIATIONS” at the top right, which shows one entry per association that the respective record (data model) has. In this case the record of the city “Aachen” is associated with “COUNTRY” and “CAPITALTO”.
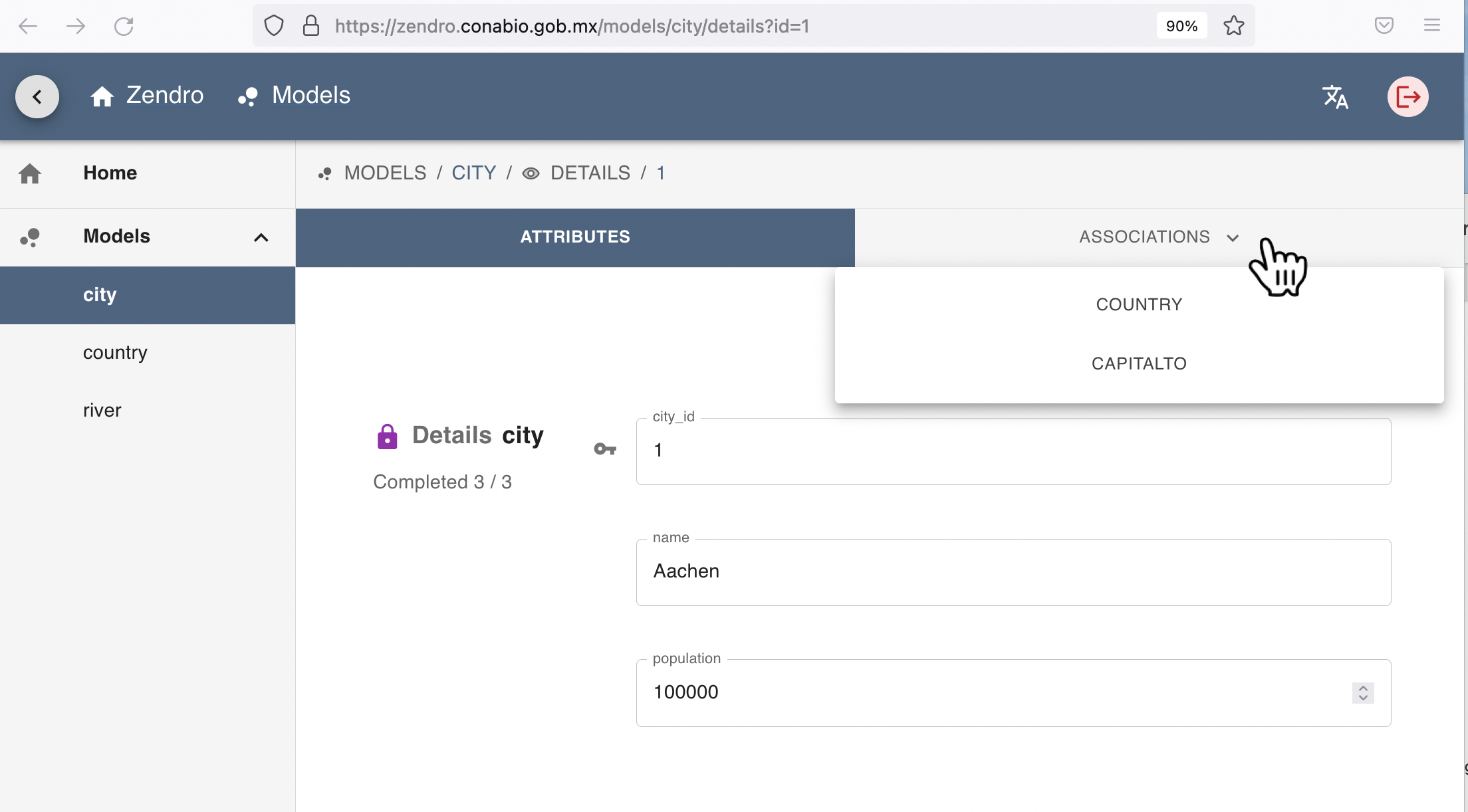
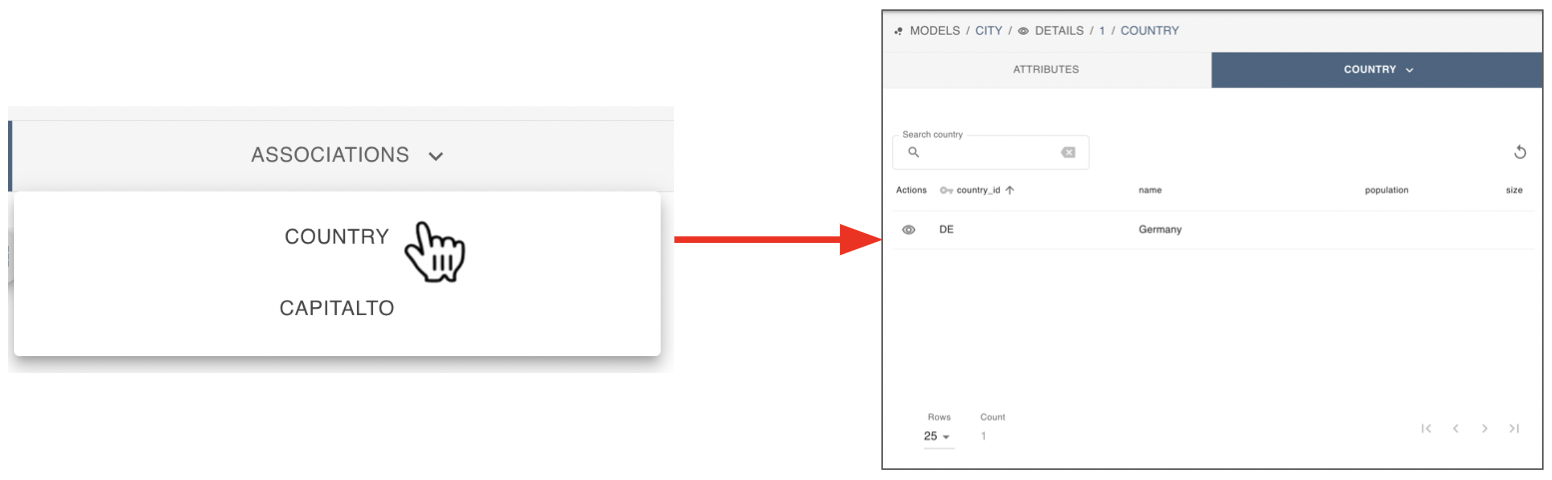
Upon clicking on an association name the user can now inspect the associated records. If this is an association of many records, i.e. one-to-many or many-to-many association type, a table is shown just like the main table. This table has the same sorting, search, and pagination functions as the data model’s main table shown before.
Editing data
Modify or delete existing records
For a user with all Create, Read, Update, and Delete permissions, the main table offers the user the option to open the detailed view (“eye” icon), edit (“pencil” icon), or delete (“trash” icon) a given record:
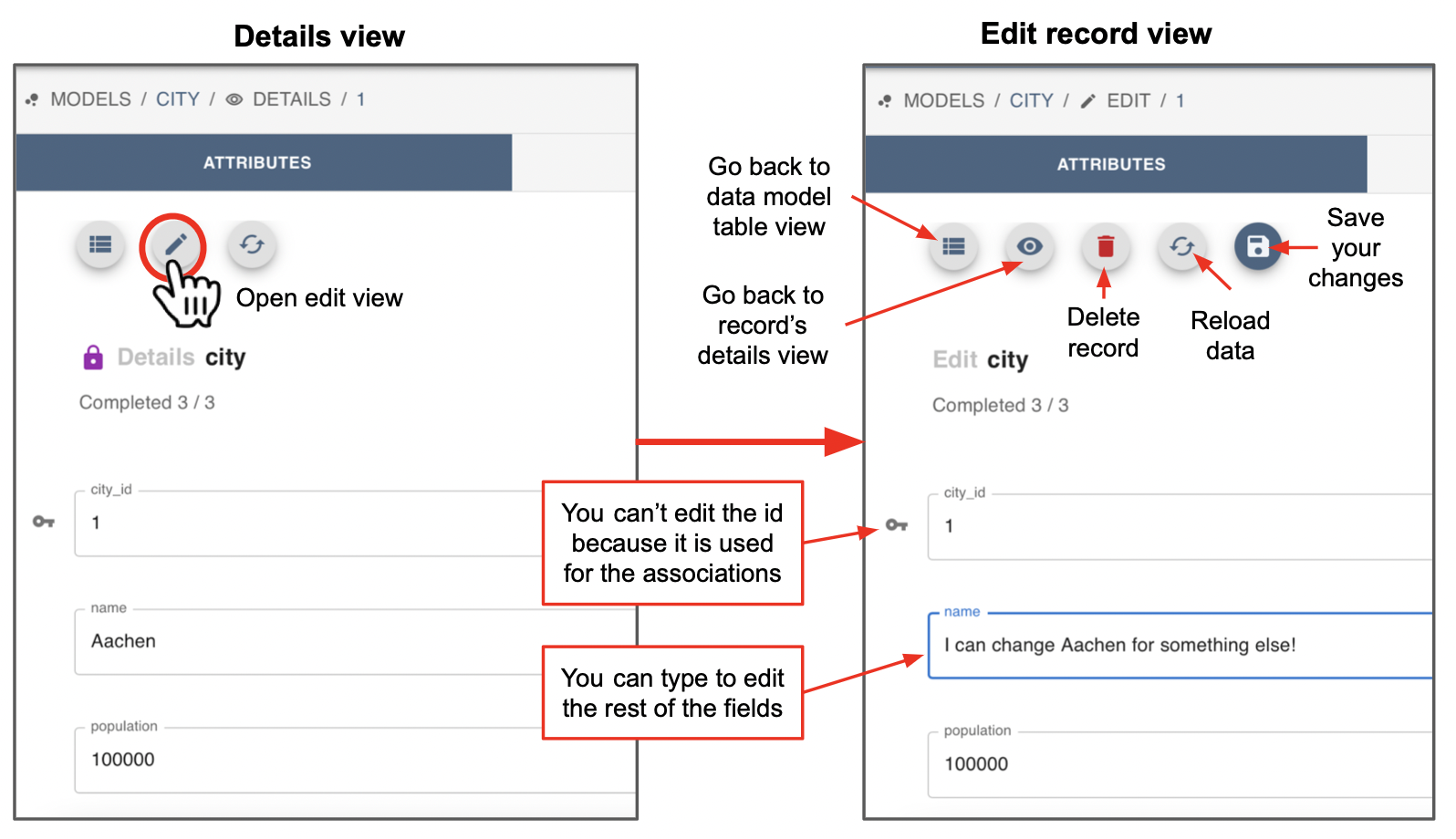
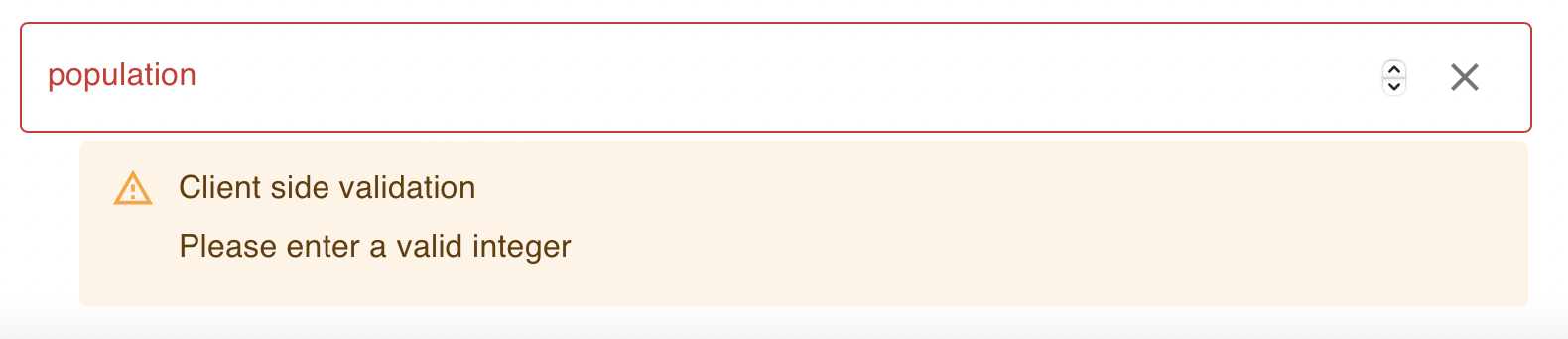
Clicking on the “pencil” icon either in the data model’s main table or in the detail view will open the edit form, pre-filled with the selected record’s data. Here the user can change the data, and a validation error will show up if the data is invalid.
For example, if we try to introduce text in the “population” field, which is defined as an integer, we would be asked to instead enter a valid integer.
All fields can be modified in this form, except the id which is the key linking to the record associations.
To edit the associations, on the “ASSOCIATIONS” tab click the name of the data model where the record to be associated is, for example “country”.
After clicking it, the user is shown a modified version of the data model’s main table, in which an additional column enables the association or dissociation of records with the currently edited one. Associated records are marked with a “link chain” icon, and not associated records with a “broken chain link” icon. In this table the user can mark several associations to be executed once the “save” button is clicked.
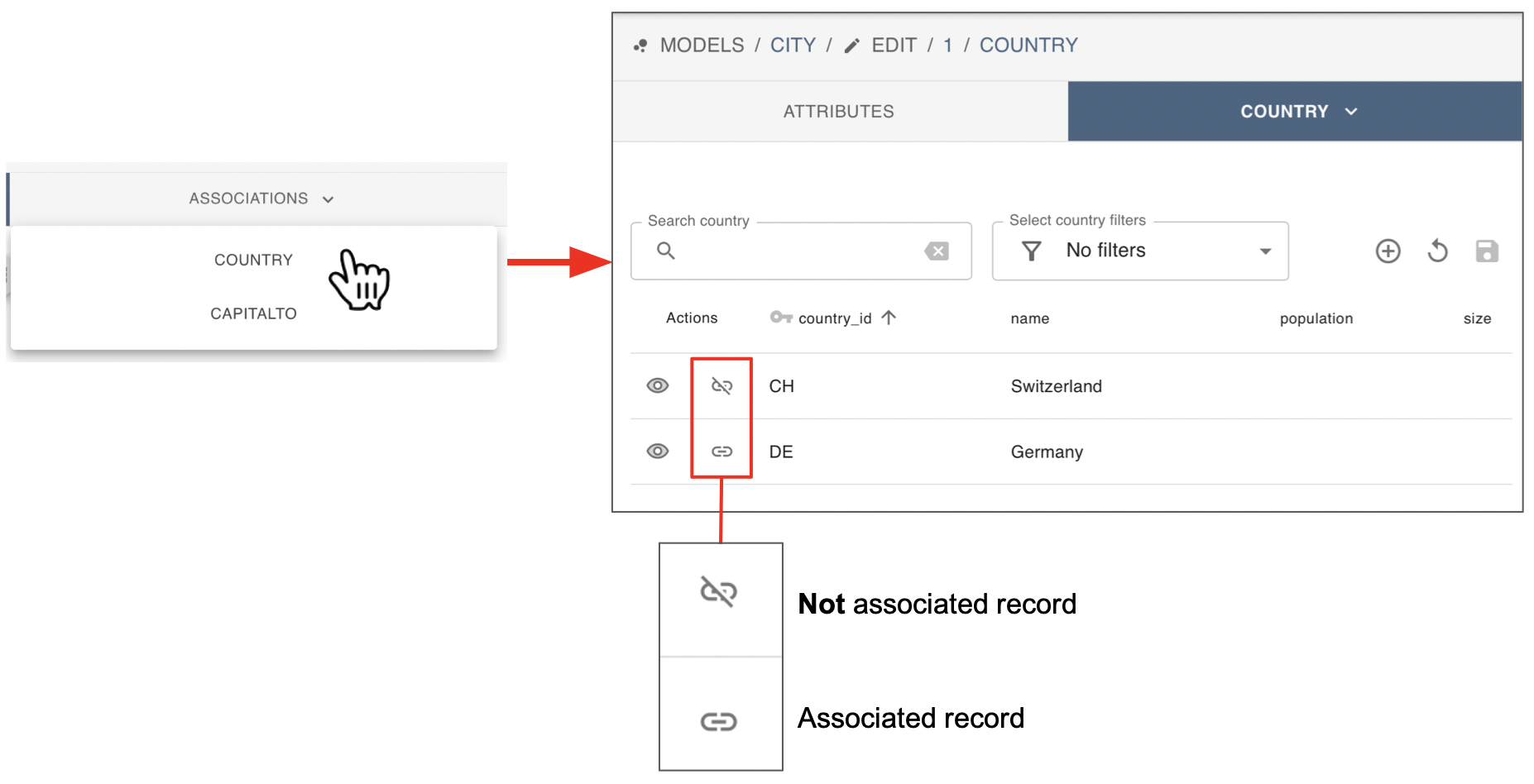
Once any of the associated/not associated icons is clicked, they revert to their respective counterpart, a connected chain link becomes a broken one and vice versa. To highlight that these are to be persisted changes the converted icons are highlighted in color, green connected chain link icons indicate that an association with the respective record shall be established, while red broken chain link icons indicate the opposite.
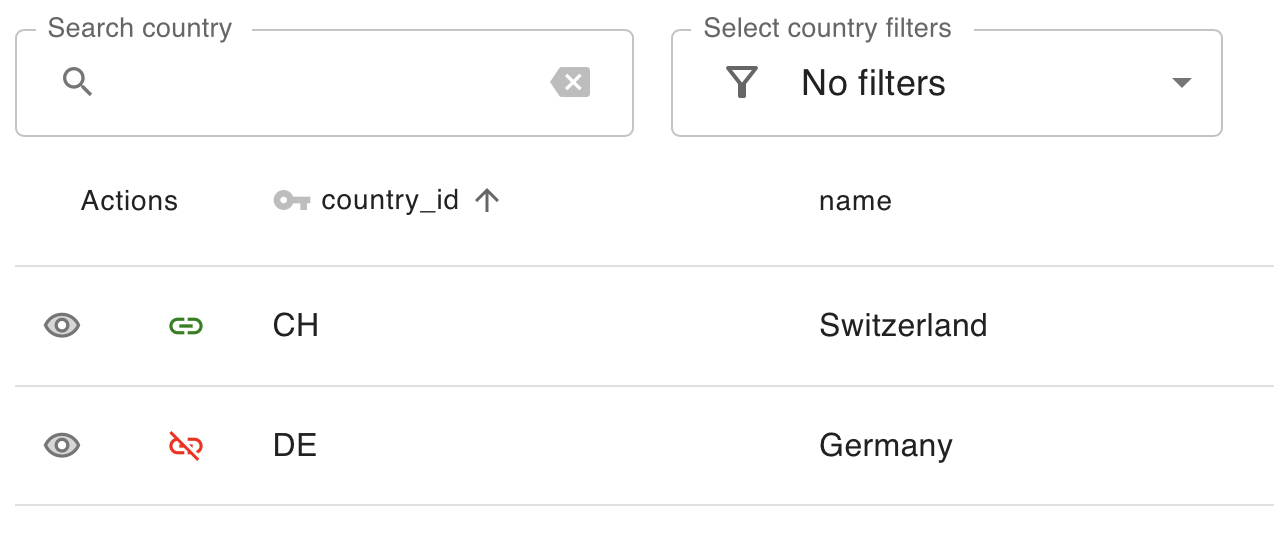
The user can paginate through the whole set of records of the respective association and mark as many change operations as wished for. They will be collected and carried out, once the save button is clicked. Additionally the user can apply a variety of filters to the table. This includes filtering for already associated records as well as filtering those records that have been marked to be added or removed as an association.
Once the desired associations have been made, click on the “save” icon at the top right menu:
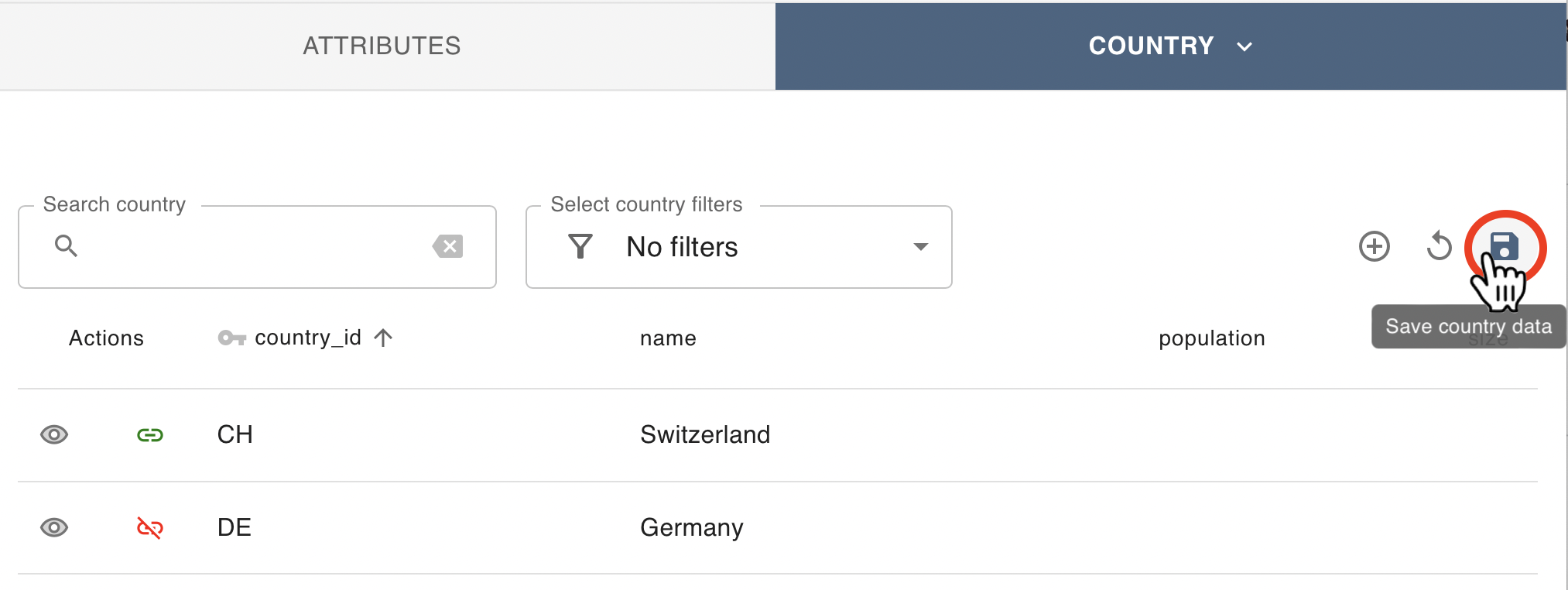
Alternatively, if the record you wish to associate to does not exist, then it is possible to manually create it by clicking on the “+” icon at the top right menu:
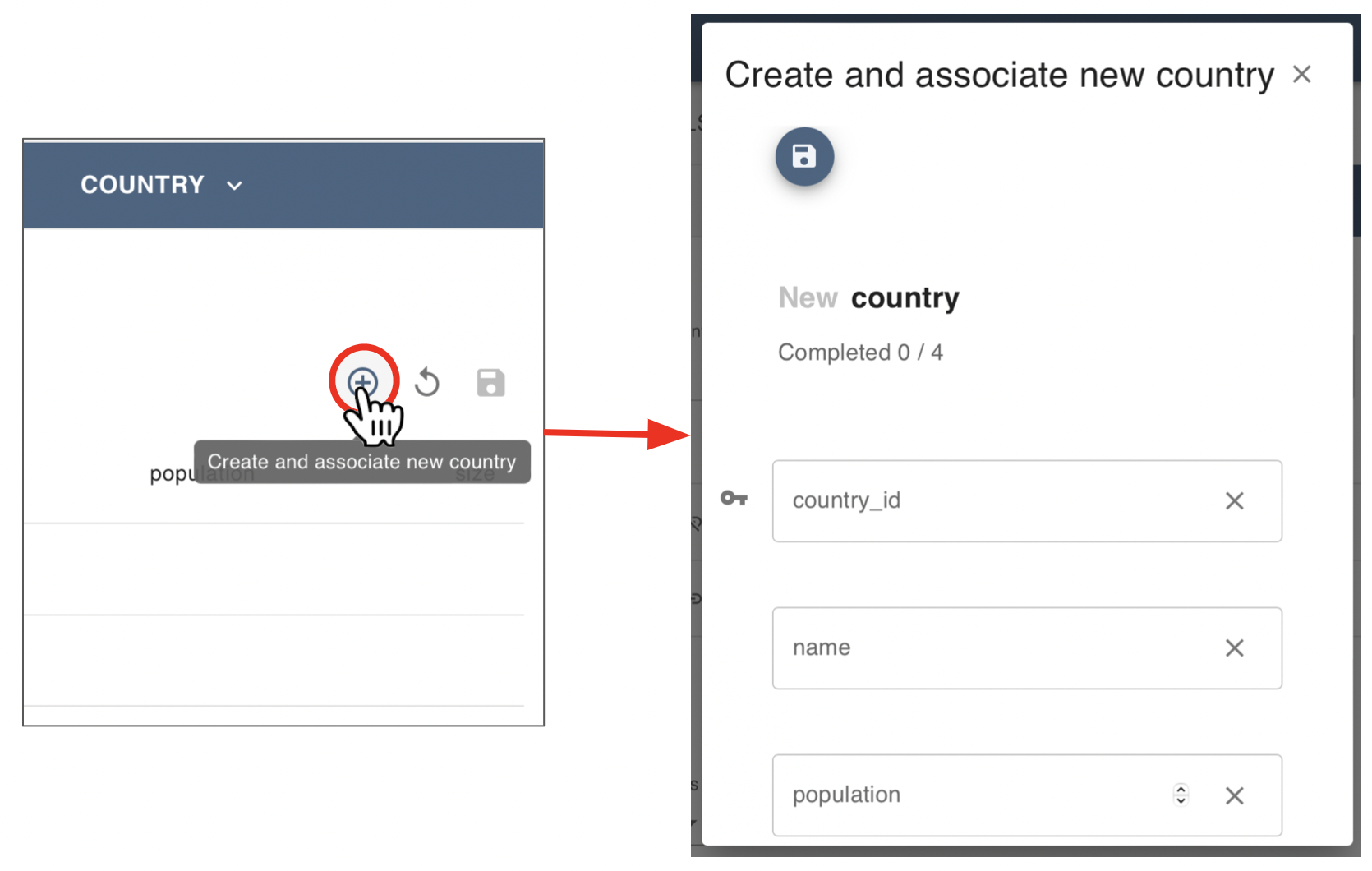
Add new records
If your user has edit permissions, on the top bar of the main data model table you will see the following buttons to Reload the data (“circle arrow” icon), Add new record (“+” icon), Import data (“bold top arrow” icon), Download data as csv (“bold down arrow” icon) and Download the model template (“light down arrow” icon). If your user only has reading access you will only see the Reload and Download icons.
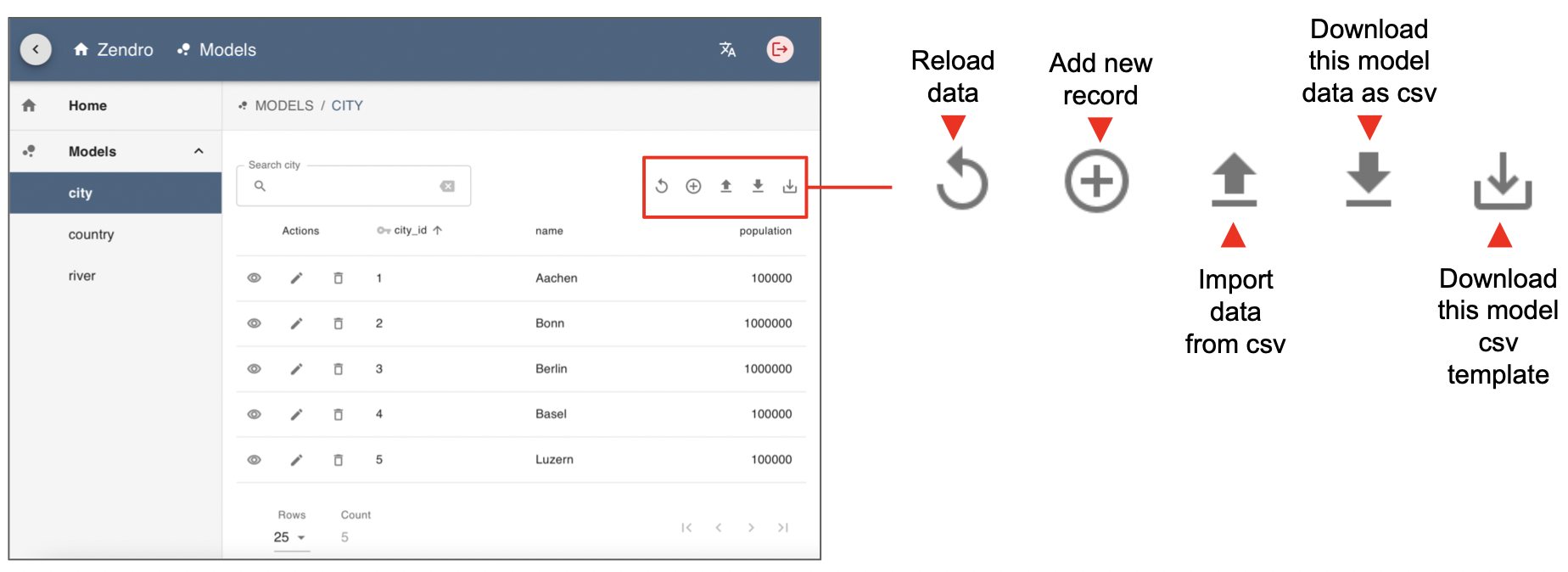
Notice that these buttons work independently for each data model table. That is, if you are in the “city” model you would be able to create or download records of the city table, but if you want to add a country you have to click in the “country” model in the left side menu.
Add a single record manually
The “+” icon enables the user to Add a single new data record, to the current data table. Upon clicking it, the user is presented with a form where the values for each field of the new record can be entered.
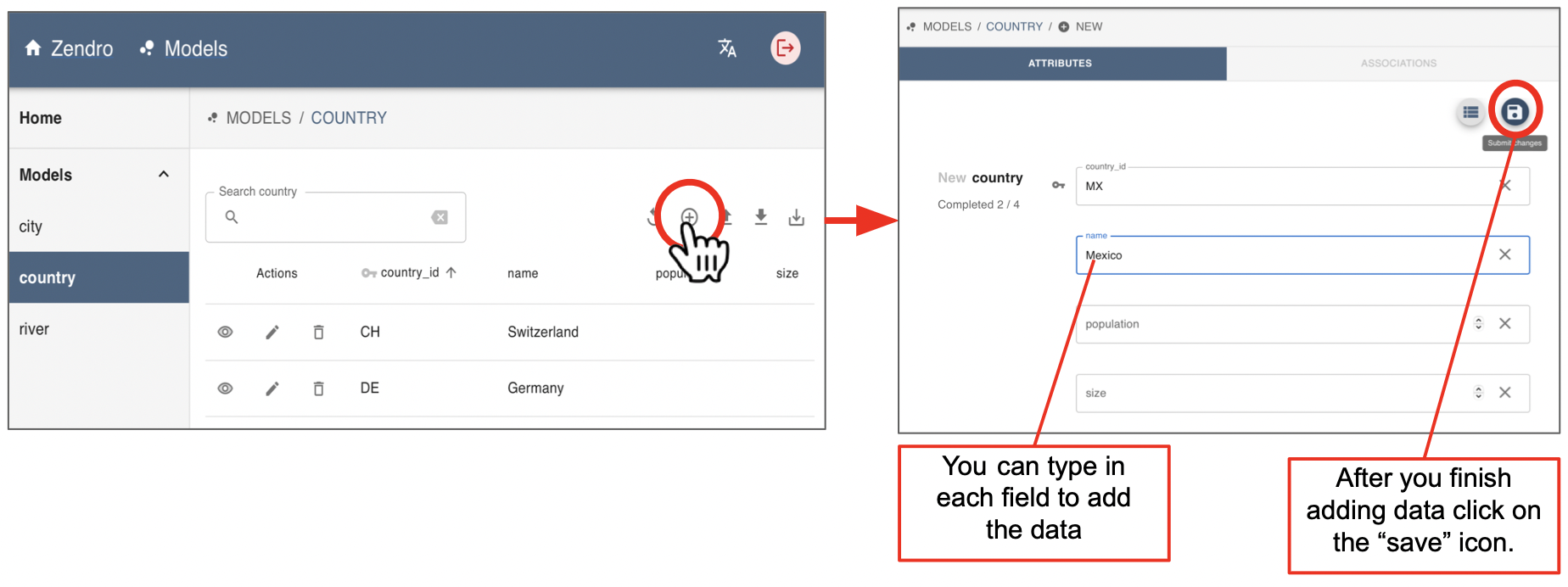
If invalid data has been entered and the user attempts to save that invalid data, validation error messages are shown as in the example above when we edited and existing record.
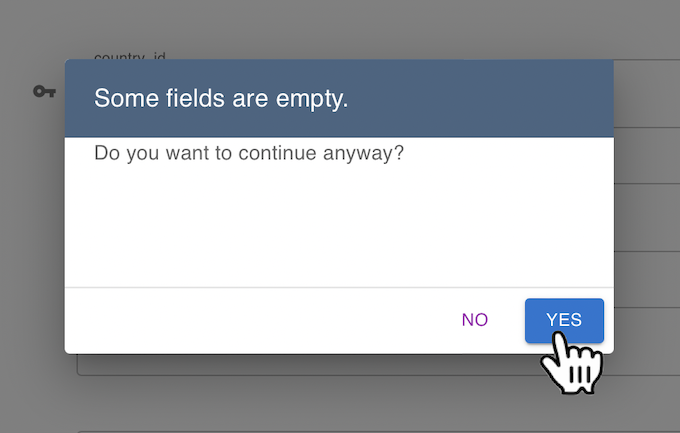
Once you finish typing the data click on the “save” icon. You don’t need to add data to all fields, but you will be asked if you are sure you want to leave some fields blank. Click “yes” to proceed:
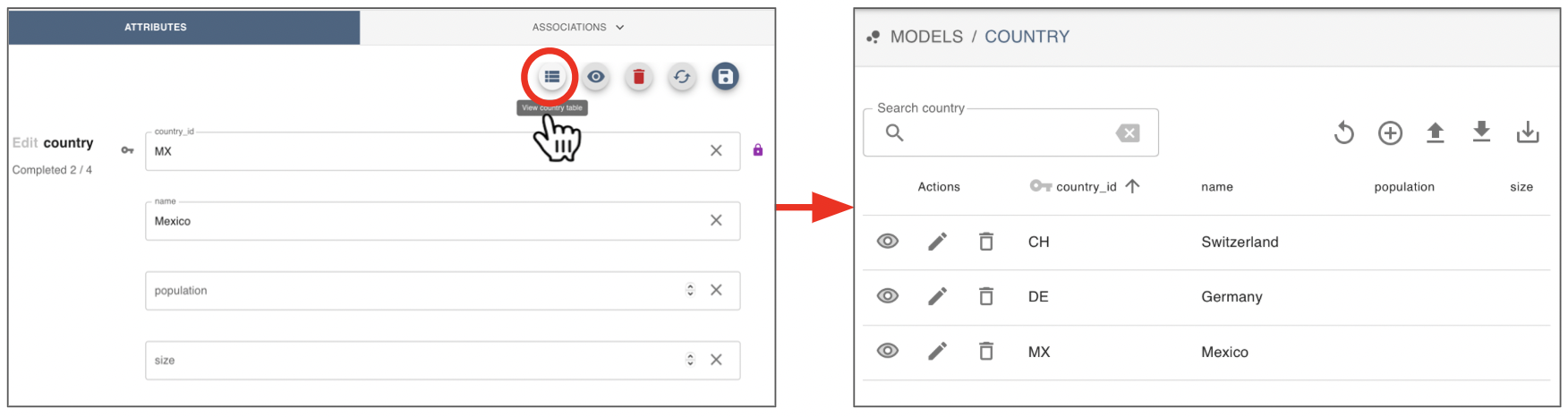
Your new record will be saved. You can click on the “table” icon on the top to see the country table again:
Add several records from a file
Adding single records one by one is useful sometimes, but many users want to add data in bulk. Users often have data in tables that were created in MS Excel, recorded with a digital device or by any other mean. You can import this data into Zendro from an Excel file (.xlsx), a comma separated value file (.csv) or a json file. Here we will cover the first two.
The .xlsx or .csv data file is expected to follow these requirements:
- Column names in the first row must correspond to model attributes (i.e. column names in the Zendro main table for that model). For associations, corresponding column name should be
add<associationName>, e.g.addCountriesfor assciationNamecountries. - Empty values should be represented as
NULL. - All fields should be quoted by
". However, if field delimiter and array delimiter do not occur in fields with String type, namely characters could be split without ambiguity, then no quotes are necessary. For example, if the field delimiter is,and one String field is likeZendro, excellent!, then without the quotation mark, this field will be split as two fields. So in such case these String fields must be quoted. - Default configuration: LIMIT_RECORDS=10000, RECORD_DELIMITER=”\n”, FIELD_DELIMITER=”,”, ARRAY_DELIMITER=”;”. They can be changed in the config file for environment variables.
- Date and time formats must follow the RFC 3339 standard.
Additionally, if you are uploading your data from a csv file:
- String (text) records should be quoted by
". For example"Ingredient A, Ingredient B"instead ofIngredient A, Ingredient B. However, if there are no commas (,) within any single record, then the quotes are not necessary. "NULL"should be quoted.
In order to get the field names right and check what type each one is (e.g. integer, character, etc), you can Download the model template by clicking in the “light down arrow” at the top right panel of the main data model table. You will be prompted to download a csv file named after the table you are downloading, for example “river”. You can open this file in your favourite spreadsheet processor (e.g. Excel).
It will have the the column names you need in the first row, and the data type in the second. Notice that if your data model has associations, the foreign keys of associating records will be shown as columns too. For example because the model “river” is associated with one or more “countries” you have to provide the addCountries in the last column. If we fill this example with a list of Mexican rivers, this means that the addCountries field should include Mexico’s country id, which is “MX” according to the “country” data model table.
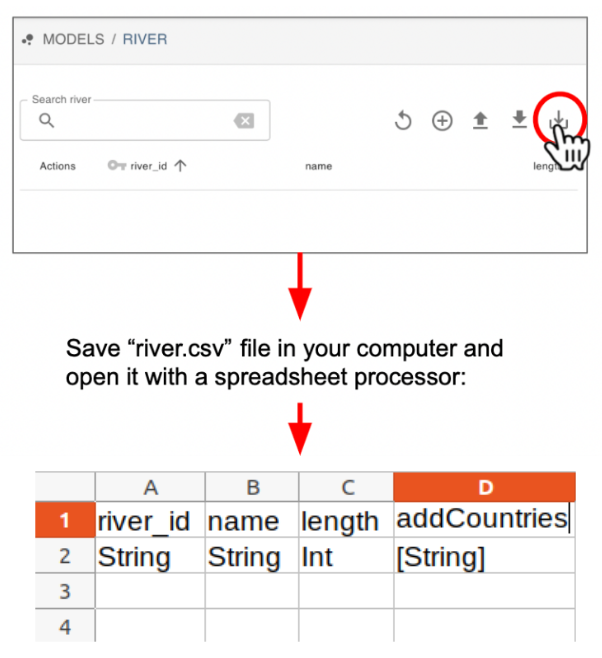
Next, edit this csv file to add your data. You can do this in a spreadsheet processor (e.g. Excel).
Make sure to:
- Leave the first line (column names) as it is.
- Replace the second row with data, but remember: the second row tells you what type of data Zendro is expecting for each field, e.g.
Int= integer numbers, andString= text. - Follow the data requirements detailed above.
Save as an .xlsx file. It should be ready to upload it to Zendro!
Alternatively, if you are using a Text Editor (e.g. NotePad, Sublime Text) or a command line program (e.g. R, python) to generate a .csv, your file should look something like this (here we quoted all fields to prevent any ambiguity):
river_id,name,length,country_ids
"47","Tonalá","82","NULL"
"48","Tuxpan","150","NULL"
"49","Verde","342","NULL"
"50","Yaqui","410","NULL"
Save it as an .csv file. It should be ready to upload it to Zendro!
Note: you can also save as csv file from Excel, but make sure you add the " if any of your strings (text) have , within them.
To finally upload your data to Zendro click on Import data (“bold top arrow” icon) of the top right menu, select your file and click Upload:
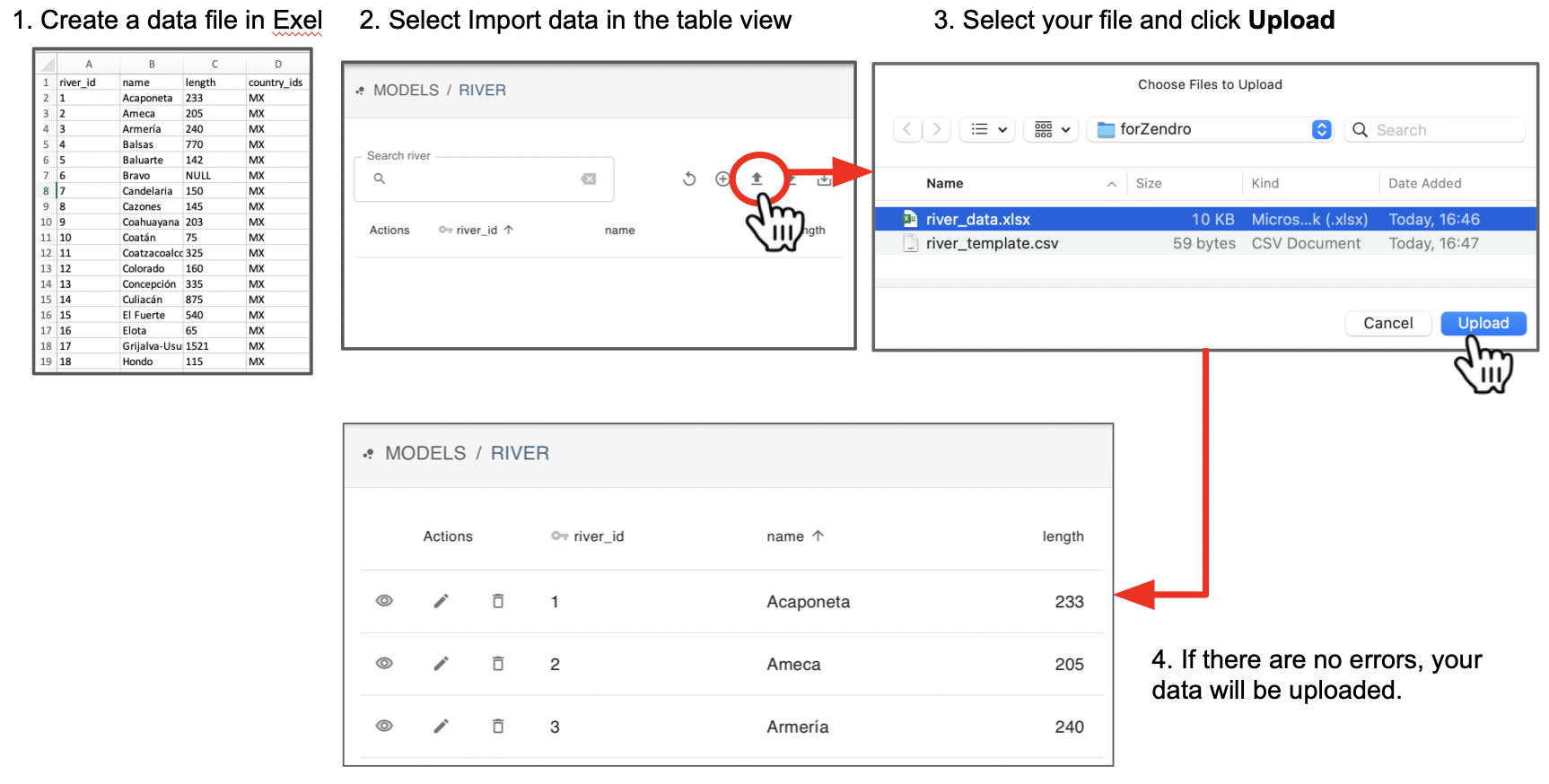
If there are no errors your data will be uploaded. Click the Reload button of the top right menu if you can’t see it.
If there are errors you will be told what’s the problem. Check your data and try again.
Note: the maximum allowed upload size and other variables you see our interact with in the graphical interface are customizable when setting up Zendro. You (or your sys admin) can learn more about this int he Environment variables section of the documentation.
Download data
To download data, click on the Download data button (bold down arrow). You will be prompted to select a directory and file name where to save the data.
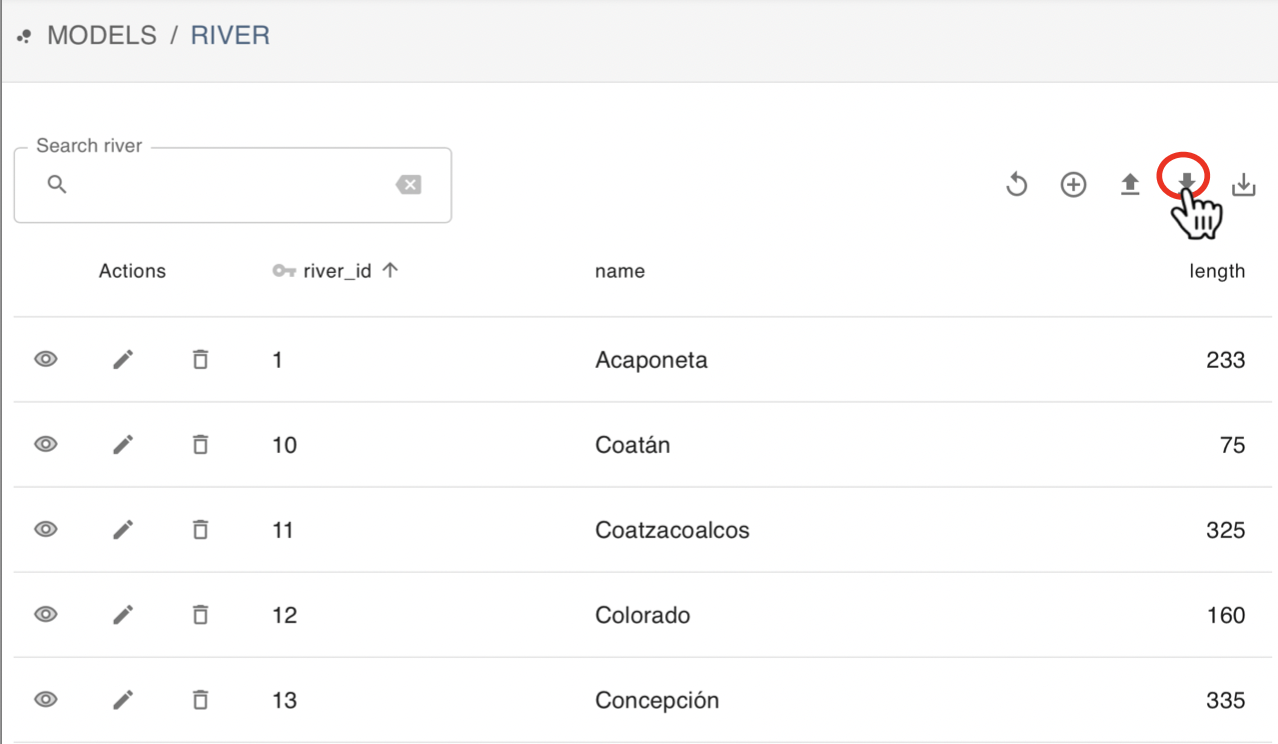
The data will be saved in .csv format, which you can open in Excel or import it to statistical software like R. Notice that this only downloads the data of any given table at a time. Complex queries to download specific data or to show columns from different models in a single table, can be done through Zendro’s API. Check Zendro home documentation for tutorials on how to do this.