GraphQL & API
Table of contents
Introduction to GraphQL and querying the API
GraphQL is a query language for Application Programming Interfaces (APIs), which documents what data is available in the API and allows to query and get exactly the data we want and nothing more.
This tutorial provides a short introduction to GraphQL, but we recommend you to explore the GraphQL documentation and other introductory resources like this one to learn more.
In the GraphQL API Queries are written in the GraphQL language, and the result (the data) is given back in JSON format. JSON (from JavaScript Object Notation) is a standard text-based format for representing structured data. It is widely used for transmitting data in web applications, and it can easily be reformatted into tables or data frames within programming languages like R or Python.
Zendro provides a GraphQL API web interface, called GraphiQL, which is a Web Browser tool for writing, validating, and testing GraphQL queries.
You can live-try an example here, which is the API that we will be using in this and other tutorials: https://zendro.conabio.gob.mx/api/graphql.
Zendro’s GraphQL API allows not only to query the data, but also to create, modify or delete records (mutate). This is available only with authentication (i.e. logging in with edit permissions), and it won’t be covered in this tutorial, but you can check other Zendro’s How to guides for details on mutations.
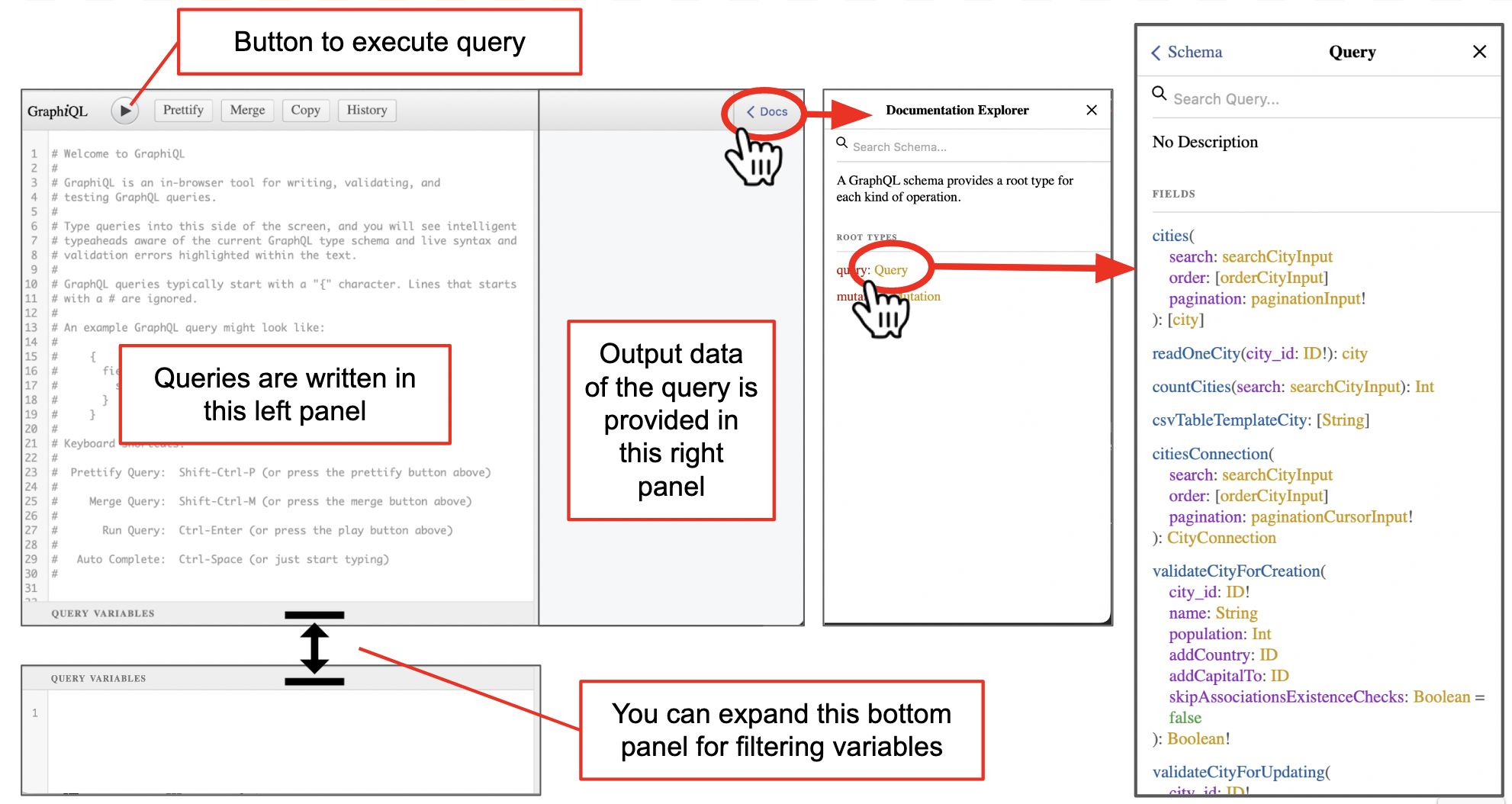
GraphiQL web interface
The GraphiQL API web interface has the following main components:
- A left panel where you can write your query in GraphQL format.
- A right panel where the result of the query is provided in JSON format.
- A play button to execute the query. Its keyboard shortcut is
Ctr+E. - A Documentation Explorer side menu, which you can show or hide clicking on “Docs” in the top right corner.
Data in GraphQL is organised in types and fields within those types. When thinking about your structured data, you can think of types as the names of tables, and fields as the columns of those tables. The records will be the rows of data from those tables. You can learn more in the GraphQL documentation.
A GraphQL service is created by defining types and fields on those types, and providing functions for each field on each type.
The documentation explorer allows to examine what operations (e.g. query, mutation) are allowed for each type. Then, clicking on Query will open another view with the details of what operations are available to query the data. In this view, all types available in a given dataset are listed in alphabetical order, with the operations than can be done within them listed below.
In the example of the image above, we can see that the first type is cities. Types can contain elements or arguments, which are specified inside parentheses (). Some of these may be required arguments (marked with !), such as pagination.
You can extend the bottom panel (“Query variables”) to provide dynamic inputs to your query. Learn more.
Writing queries
The GraphQL documentation includes plenty of resources to learn how to build queries and make the most out of the power of GraphQL. Below we provide just a short summary, after which we recommend you to explore the GraphQL documentation to learn more. Feel free to try your queries in our Zendro Dummy API we set up for tests.
GraphQL syntax tips:
- Queries and other operations are written between curly braces
{}. - Types can contain elements or arguments, which are specified inside parentheses
(). - Use a colon
:to set parameter arguments (e.g.pagination:{limit:10, offset:0}). - Use a hashtag
#to include comments within a query, which are useful to document what you are doing. - A query should provide at least one type (e.g.
rivers), at least one a field (e.g.names), and any mandatory arguments the types have (marked with!in the Docs). - In Zendro
paginationis a mandatory argument. It refers to the number of records (limit) the output returns, starting from a givenoffset. If you don’t specify the offset, by default this will beoffset:0
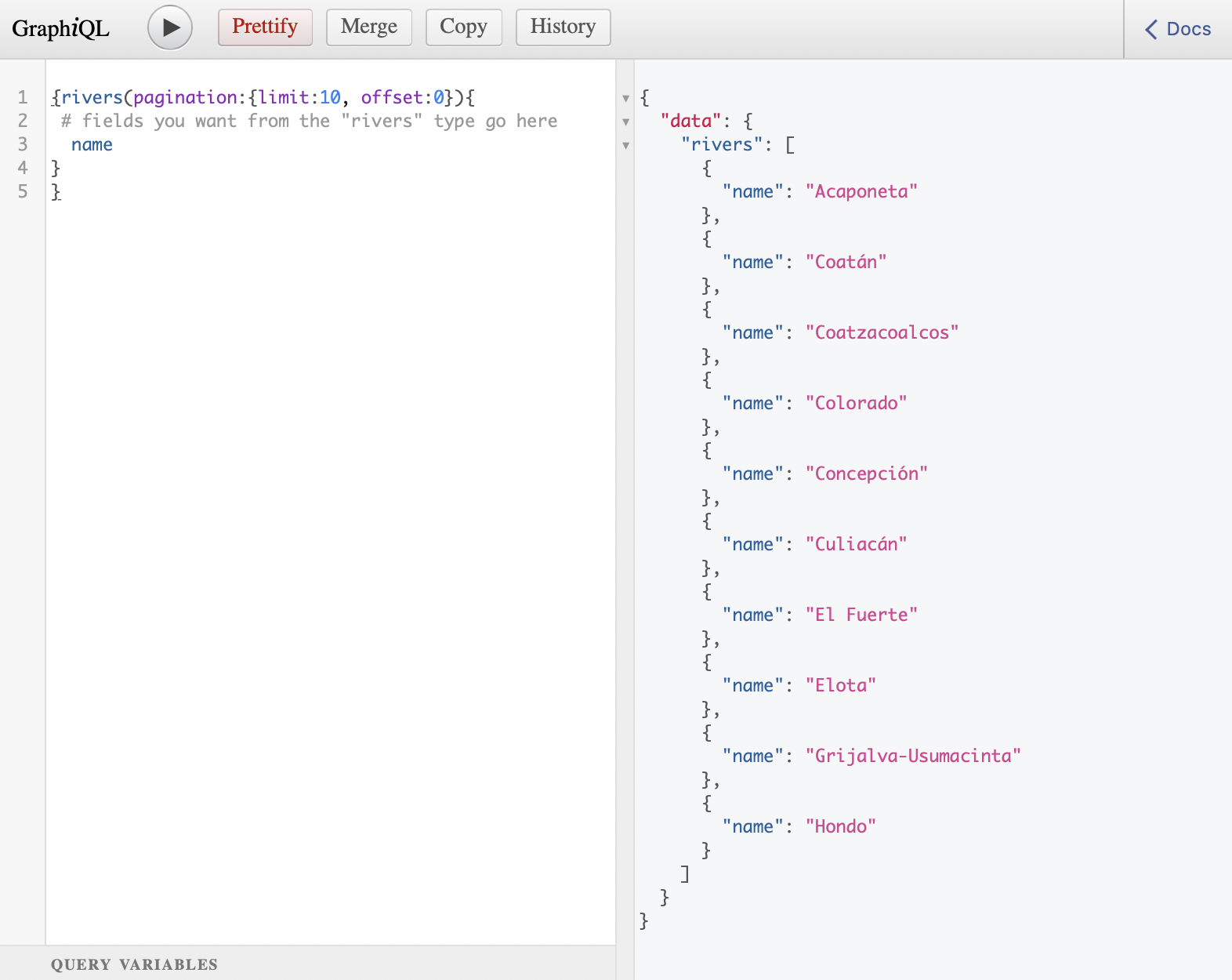
A simple query will look like this:
{rivers(pagination:{limit:10, offset:0}){
# fields you want from the "rivers" type go here
name
}
}
Copy-pasting and executing the former query in GrapiQL looks like the following image. That is, we got the names of the first 10 rivers of the data :
But how did we know that name is a field within rivers? There are two options:
Option 1: Check the Docs panel
Click on Query, then look for the type you want (in this example rivers), and then click on [river]. This will open the list of fields available for it, along with their documentation:
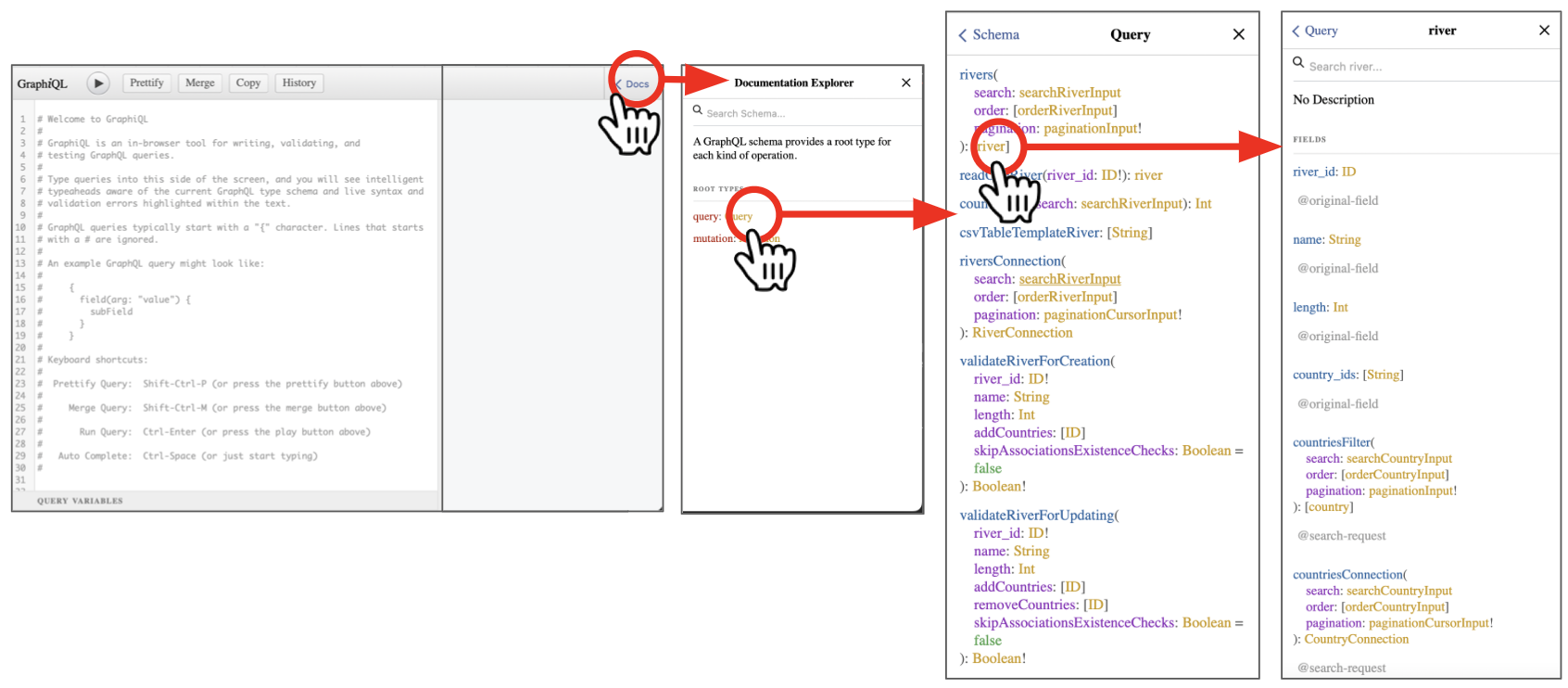
Option 2: autocomplete while you type
If you want to know what fields are available for the type rivers you can hold ctrl+space within the curly braces {} after rivers(pagination:{limit:10, offset:0}). A menu will appear showing you all possible fields.
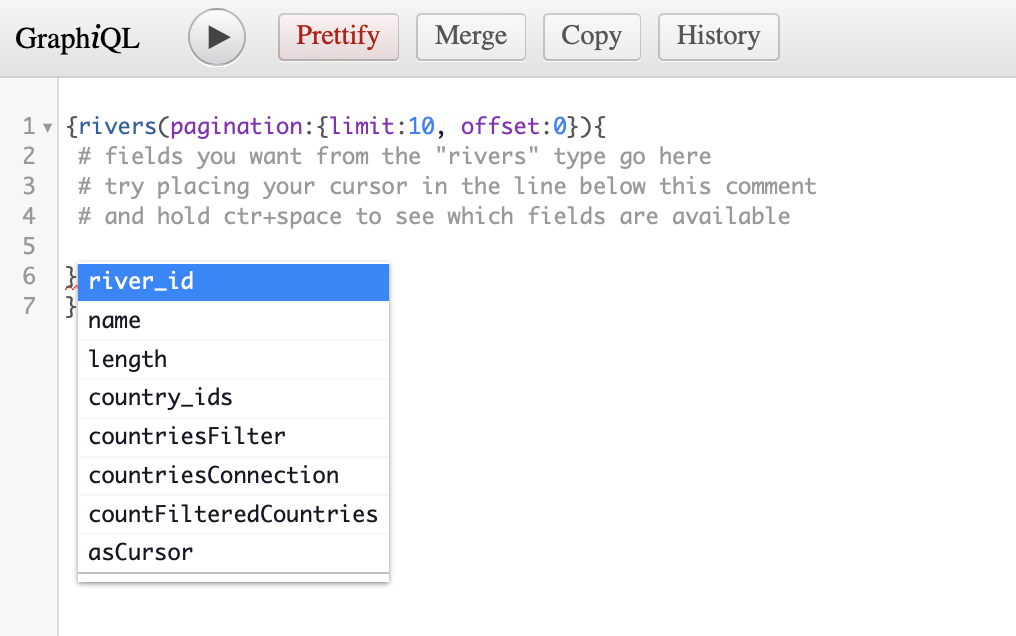
In this example, we can get the fields river_id, name and country_ids. The rest of the list is related to countries, because rivers is associated with countries, and therefore we can build a more complex query with them.
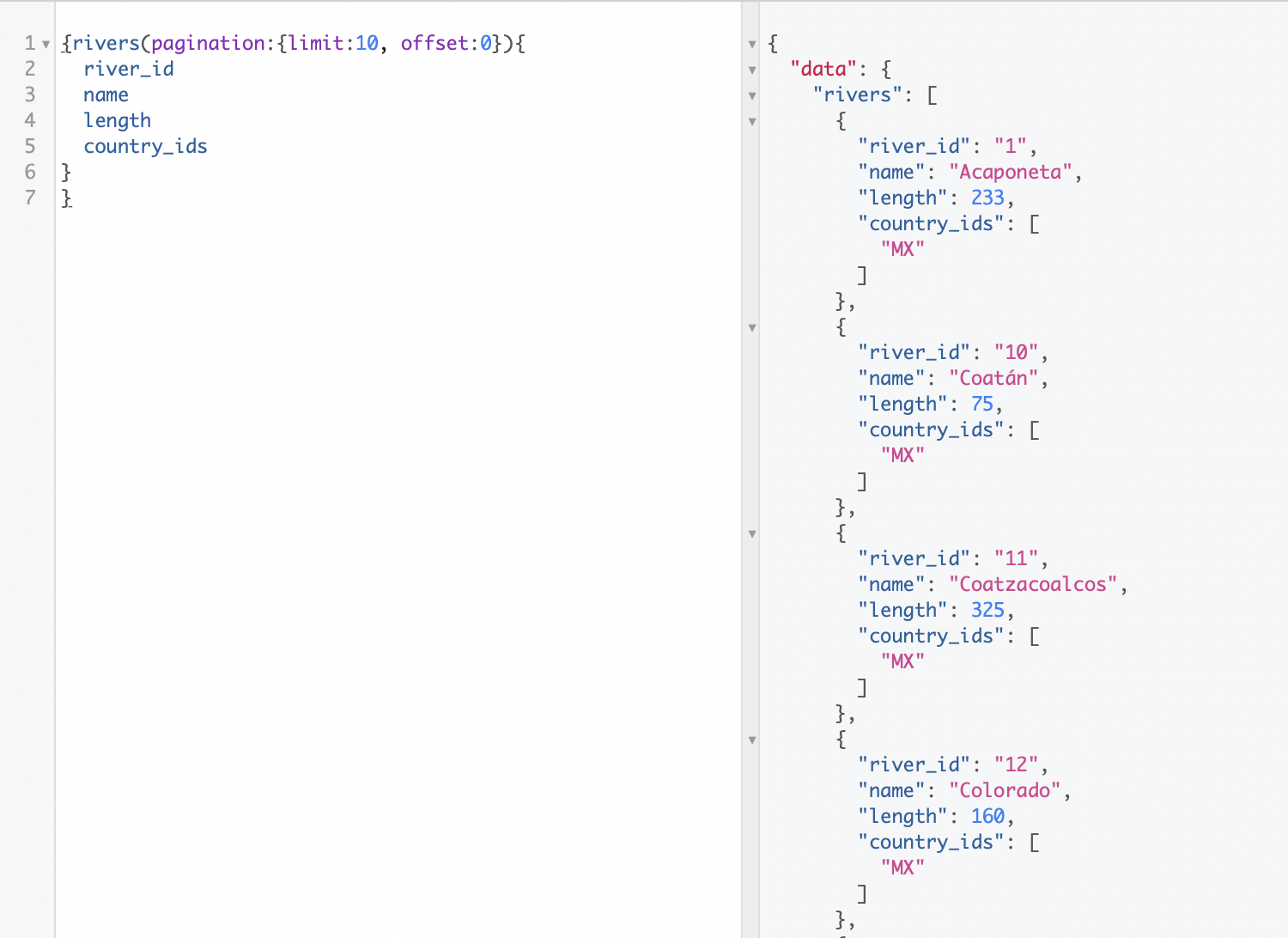
But first, lets build a query to give us back the fields river_id, name and country_ids from the type river, like this:
{rivers(pagination:{limit:10, offset:0}){
river_id
name
length
country_ids
}
}
As a result of the query, for each of the 10 first rivers (10 because we set limit:10) of the data we will get its id, name, length, and the id of any country it is associated to:
Extracting data from different types (i.e. dealing with associations)
GraphQL can get fields associated with a record in different types, allowing us to get the data with only the variables and records we need form the entire dataset. For example, we can get the name and length of a river, but also the name and population of the countries it crosses.
Extracting data from associated types depends on if the association is one to one (a city belongs to one country) or one to many (a river can cross many countries).
One to one
When the association is one to one the associated data model will apear as just another field, . For example each city is associated with one country, therefore country is one of the fields available within cities.
If you look at the Docs, you will notice that it is not just another field, but that you need to provide it with an input search.
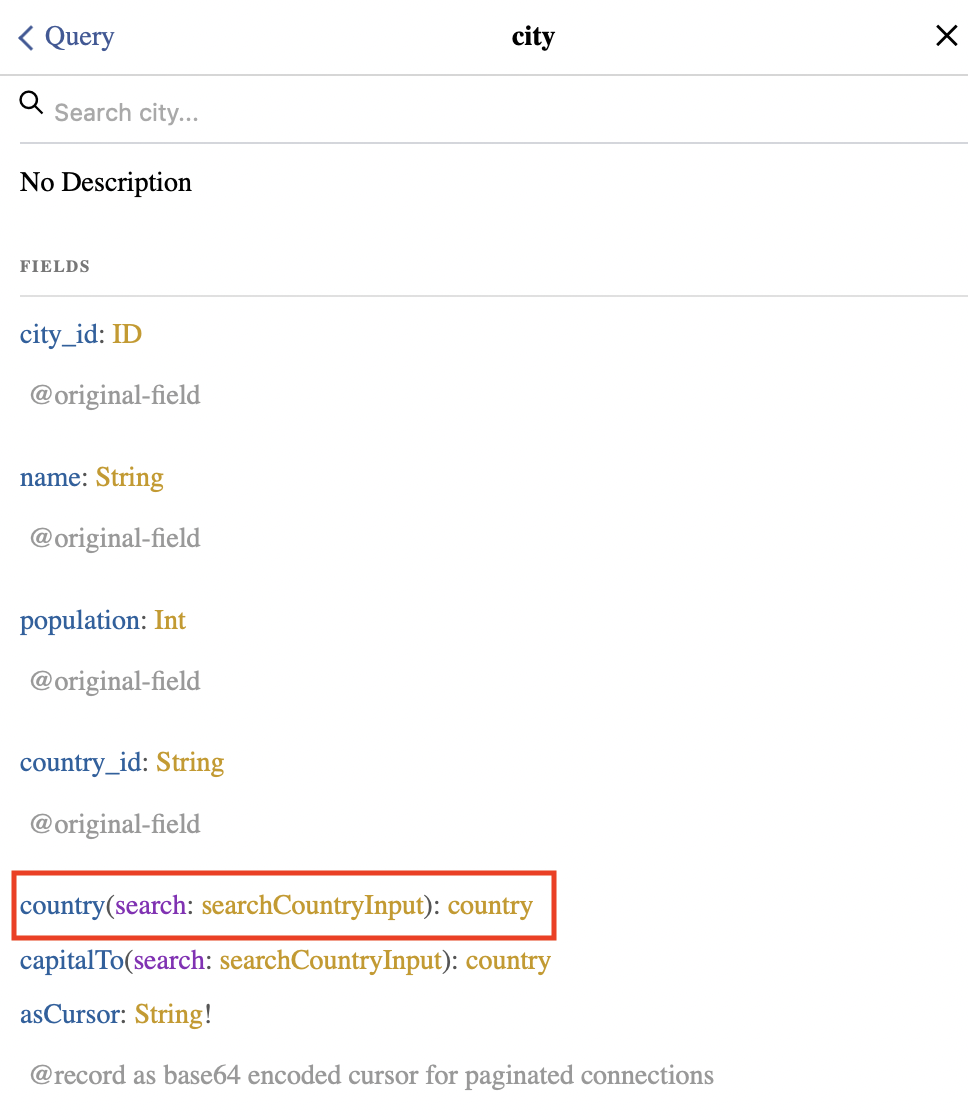
In this case we want to look for what country this is associated, and we know that the field in common (i.e. the key) is the country_id, therefore your search should look like:
{
cities(pagination:{limit:10, offset:0}){
city_id
name
population
country(search:{field:country_id}){
name
population
}
}
}
One to many
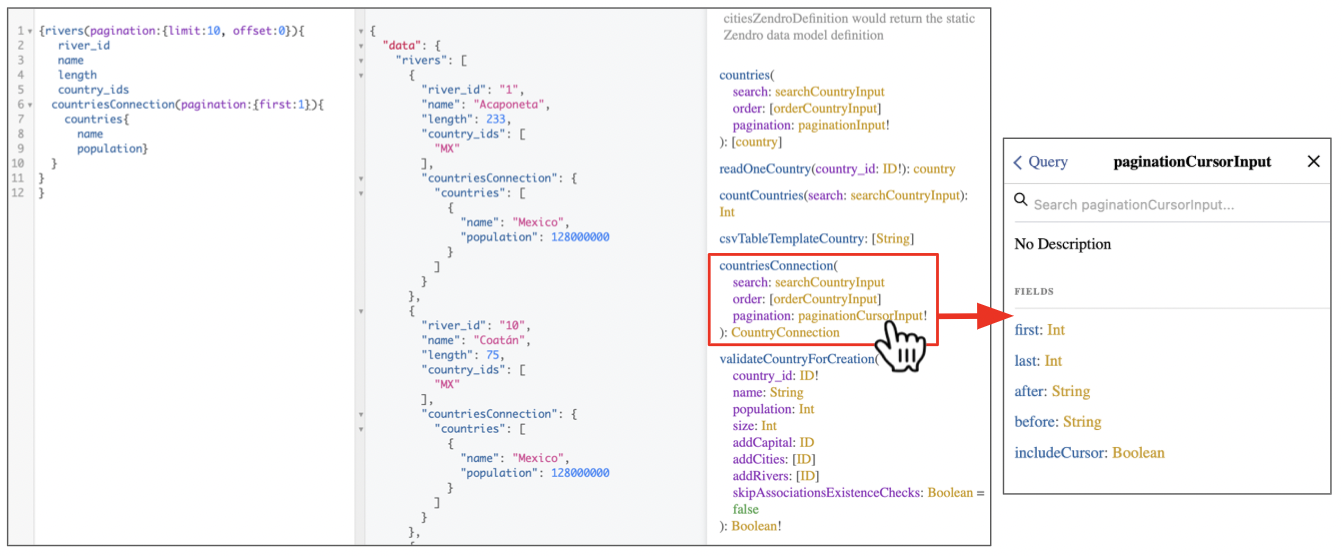
When the association is one to many there would be a Connection for each each association the model has. For example, to see the countries a river is associated to we need to use countriesConnection:
{rivers(pagination:{limit:10, offset:0}){
river_id
name
length
country_ids
countriesConnection(pagination:{first:1}){
countries{
name
population}
}
}
}
Remember to check the Docs for any mandatory argument. In this case pagination is mandatory. You can check what you are expected to write in its paginationCursorInput by clicking on it in the documentation. Also check the pagination documentation for details on how to use this argument.
After you execute the query, you will get the same data we got for each river before, but also the data of the country (or countries, if it were the case) it is associated to.
In the above examples all the arguments are inside the query string. But the arguments to fields can also be dynamic, for instance there might be a dropdownn menu in an application that lets the user select which City the user is interested in, or a set of filters.
To improve run time, GraphQL can factor dynamic values out of the query, and pass them as a separate dictionary. These values are called variables. Common variables include search, order and pagination. To work with variables you need to do three things:
- Replace the static value in the query with
$variableName - Declare
$variableNameas one of the variables accepted by the query - Pass
variableName: valuein the separate, transport-specific (usually JSON) variables dictionary
Check the official documentation for examples.
As you can see, you can write much more complex queries to get the data you want. Please explore the GraphQL documentation or many other resources out there to learn more. The above examples should get you going if you want to get data to perform analyses in R or Python.
Before trying to download data from R, Python or any other programming language using the GraphQL API, we recommend writing the query to the GraphiQL web interface and making sure it returns the desired data as in the right panel in the image above.
Next step? Check Zendro How to guides for tutorials on how to use the GraphQL API from R or Python to explore and analyse data stored in Zendro.